 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona Jailbreaking in Large Language Models
Jan 23, 2026Large Language Models (LLMs) are increasingly deployed in domains such as education, mental health and customer support, where stable and consistent personas are critical for reliability. Yet, existing studies focus on narrative or role-playing tasks and overlook how adversarial conversational history alone can reshape induced personas. Black-box persona manipulation remains unexplored, raising concerns for robustness in realistic interactions. In response, we introduce the task of persona editing, which adversarially steers LLM traits through user-side inputs under a black-box, inference-only setting. To this end, we propose PHISH (Persona Hijacking via Implicit Steering in History), the first framework to expose a new vulnerability in LLM safety that embeds semantically loaded cues into user queries to gradually induce reverse personas. We also define a metric to quantify attack success. Across 3 benchmarks and 8 LLMs, PHISH predictably shifts personas, triggers collateral changes in correlated traits, and exhibits stronger effects in multi-turn settings. In high-risk domains mental health, tutoring, and customer support, PHISH reliably manipulates personas, validated by both human and LLM-as-Judge evaluations. Importantly, PHISH causes only a small reduction in reasoning benchmark performance, leaving overall utility largely intact while still enabling significant persona manipulation. While current guardrails offer partial protection, they remain brittle under sustained attack. Our findings expose new vulnerabilities in personas and highlight the need for context-resilient persona in LLMs. Our codebase and dataset is available at: https://github.com/Jivnesh/PHISH
Mitrasamgraha: A Comprehensive Classical Sanskrit Machine Translation Dataset
Jan 12, 2026While machine translation is regarded as a "solved problem" for many high-resource languages, close analysis quickly reveals that this is not the case for content that shows challenges such as poetic language, philosophical concepts, multi-layered metaphorical expressions, and more. Sanskrit literature is a prime example of this, as it combines a large number of such challenges in addition to inherent linguistic features like sandhi, compounding, and heavy morphology, which further complicate NLP downstream tasks. It spans multiple millennia of text production time as well as a large breadth of different domains, ranging from ritual formulas via epic narratives, philosophical treatises, poetic verses up to scientific material. As of now, there is a strong lack of publicly available resources that cover these different domains and temporal layers of Sanskrit. We therefore introduce Mitrasamgraha, a high-quality Sanskrit-to-English machine translation dataset consisting of 391,548 bitext pairs, more than four times larger than the largest previously available Sanskrit dataset Itih=asa. It covers a time period of more than three millennia and a broad range of historical Sanskrit domains. In contrast to web-crawled datasets, the temporal and domain annotation of this dataset enables fine-grained study of domain and time period effects on MT performance. We also release a validation set consisting of 5,587 and a test set consisting of 5,552 post-corrected bitext pairs. We conduct experiments benchmarking commercial and open models on this dataset and fine-tune NLLB and Gemma models on the dataset, showing significant improvements, while still recognizing significant challenges in the translation of complex compounds, philosophical concepts, and multi-layered metaphors. We also analyze how in-context learning on this dataset impacts the performance of commercial models
Still Not There: Can LLMs Outperform Smaller Task-Specific Seq2Seq Models on the Poetry-to-Prose Conversion Task?
Nov 11, 2025Large Language Models (LLMs) are increasingly treated as universal, general-purpose solutions across NLP tasks, particularly in English. But does this assumption hold for low-resource, morphologically rich languages such as Sanskrit? We address this question by comparing instruction-tuned and in-context-prompted LLMs with smaller task-specific encoder-decoder models on the Sanskrit poetry-to-prose conversion task. This task is intrinsically challenging: Sanskrit verse exhibits free word order combined with rigid metrical constraints, and its conversion to canonical prose (anvaya) requires multi-step reasoning involving compound segmentation, dependency resolution, and syntactic linearisation. This makes it an ideal testbed to evaluate whether LLMs can surpass specialised models. For LLMs, we apply instruction fine-tuning on general-purpose models and design in-context learning templates grounded in Paninian grammar and classical commentary heuristics. For task-specific modelling, we fully fine-tune a ByT5-Sanskrit Seq2Seq model. Our experiments show that domain-specific fine-tuning of ByT5-Sanskrit significantly outperforms all instruction-driven LLM approaches. Human evaluation strongly corroborates this result, with scores exhibiting high correlation with Kendall's Tau scores. Additionally, our prompting strategies provide an alternative to fine-tuning when domain-specific verse corpora are unavailable, and the task-specific Seq2Seq model demonstrates robust generalisation on out-of-domain evaluations.
CSSL: Contrastive Self-Supervised Learning for Dependency Parsing on Relatively Free Word Ordered and Morphologically Rich Low Resource Languages
Oct 09, 2024



Neural dependency parsing has achieved remarkable performance for low resource morphologically rich languages. It has also been well-studied that morphologically rich languages exhibit relatively free word order. This prompts a fundamental investigation: Is there a way to enhance dependency parsing performance, making the model robust to word order variations utilizing the relatively free word order nature of morphologically rich languages? In this work, we examine the robustness of graph-based parsing architectures on 7 relatively free word order languages. We focus on scrutinizing essential modifications such as data augmentation and the removal of position encoding required to adapt these architectures accordingly. To this end, we propose a contrastive self-supervised learning method to make the model robust to word order variations. Furthermore, our proposed modification demonstrates a substantial average gain of 3.03/2.95 points in 7 relatively free word order languages, as measured by the UAS/LAS Score metric when compared to the best performing baseline.
DepNeCTI: Dependency-based Nested Compound Type Identification for Sanskrit
Oct 14, 2023



Multi-component compounding is a prevalent phenomenon in Sanskrit, and understanding the implicit structure of a compound's components is crucial for deciphering its meaning. Earlier approaches in Sanskrit have focused on binary compounds and neglected the multi-component compound setting. This work introduces the novel task of nested compound type identification (NeCTI), which aims to identify nested spans of a multi-component compound and decode the implicit semantic relations between them. To the best of our knowledge, this is the first attempt in the field of lexical semantics to propose this task. We present 2 newly annotated datasets including an out-of-domain dataset for this task. We also benchmark these datasets by exploring the efficacy of the standard problem formulations such as nested named entity recognition, constituency parsing and seq2seq, etc. We present a novel framework named DepNeCTI: Dependency-based Nested Compound Type Identifier that surpasses the performance of the best baseline with an average absolute improvement of 13.1 points F1-score in terms of Labeled Span Score (LSS) and a 5-fold enhancement in inference efficiency. In line with the previous findings in the binary Sanskrit compound identification task, context provides benefits for the NeCTI task. The codebase and datasets are publicly available at: https://github.com/yaswanth-iitkgp/DepNeCTI
Linguistically-Informed Neural Architectures for Lexical, Syntactic and Semantic Tasks in Sanskrit
Aug 17, 2023



The primary focus of this thesis is to make Sanskrit manuscripts more accessible to the end-users through natural language technologies. The morphological richness, compounding, free word orderliness, and low-resource nature of Sanskrit pose significant challenges for developing deep learning solutions. We identify four fundamental tasks, which are crucial for developing a robust NLP technology for Sanskrit: word segmentation, dependency parsing, compound type identification, and poetry analysis. The first task, Sanskrit Word Segmentation (SWS), is a fundamental text processing task for any other downstream applications. However, it is challenging due to the sandhi phenomenon that modifies characters at word boundaries. Similarly, the existing dependency parsing approaches struggle with morphologically rich and low-resource languages like Sanskrit. Compound type identification is also challenging for Sanskrit due to the context-sensitive semantic relation between components. All these challenges result in sub-optimal performance in NLP applications like question answering and machine translation. Finally, Sanskrit poetry has not been extensively studied in computational linguistics. While addressing these challenges, this thesis makes various contributions: (1) The thesis proposes linguistically-informed neural architectures for these tasks. (2) We showcase the interpretability and multilingual extension of the proposed systems. (3) Our proposed systems report state-of-the-art performance. (4) Finally, we present a neural toolkit named SanskritShala, a web-based application that provides real-time analysis of input for various NLP tasks. Overall, this thesis contributes to making Sanskrit manuscripts more accessible by developing robust NLP technology and releasing various resources, datasets, and web-based toolkit.
Aesthetics of Sanskrit Poetry from the Perspective of Computational Linguistics: A Case Study Analysis on Siksastaka
Aug 14, 2023


Sanskrit poetry has played a significant role in shaping the literary and cultural landscape of the Indian subcontinent for centuries. However, not much attention has been devoted to uncovering the hidden beauty of Sanskrit poetry in computational linguistics. This article explores the intersection of Sanskrit poetry and computational linguistics by proposing a roadmap of an interpretable framework to analyze and classify the qualities and characteristics of fine Sanskrit poetry. We discuss the rich tradition of Sanskrit poetry and the significance of computational linguistics in automatically identifying the characteristics of fine poetry. The proposed framework involves a human-in-the-loop approach that combines deterministic aspects delegated to machines and deep semantics left to human experts. We provide a deep analysis of Siksastaka, a Sanskrit poem, from the perspective of 6 prominent kavyashastra schools, to illustrate the proposed framework. Additionally, we provide compound, dependency, anvaya (prose order linearised form), meter, rasa (mood), alankar (figure of speech), and riti (writing style) annotations for Siksastaka and a web application to illustrate the poem's analysis and annotations. Our key contributions include the proposed framework, the analysis of Siksastaka, the annotations and the web application for future research. Link for interactive analysis: https://sanskritshala.github.io/shikshastakam/
SanskritShala: A Neural Sanskrit NLP Toolkit with Web-Based Interface for Pedagogical and Annotation Purposes
Feb 19, 2023



We present a neural Sanskrit Natural Language Processing (NLP) toolkit named SanskritShala (a school of Sanskrit) to facilitate computational linguistic analyses for several tasks such as word segmentation, morphological tagging, dependency parsing, and compound type identification. Our systems currently report state-of-the-art performance on available benchmark datasets for all tasks. SanskritShala is deployed as a web-based application, which allows a user to get real-time analysis for the given input. It is built with easy-to-use interactive data annotation features that allow annotators to correct the system predictions when it makes mistakes. We publicly release the source codes of the 4 modules included in the toolkit, 7 word embedding models that have been trained on publicly available Sanskrit corpora and multiple annotated datasets such as word similarity, relatedness, categorization, analogy prediction to assess intrinsic properties of word embeddings. So far as we know, this is the first neural-based Sanskrit NLP toolkit that has a web-based interface and a number of NLP modules. We are sure that the people who are willing to work with Sanskrit will find it useful for pedagogical and annotative purposes. SanskritShala is available at: https://cnerg.iitkgp.ac.in/sanskritshala. The demo video of our platform can be accessed at: https://youtu.be/x0X31Y9k0mw4.
A Novel Multi-Task Learning Approach for Context-Sensitive Compound Type Identification in Sanskrit
Aug 22, 2022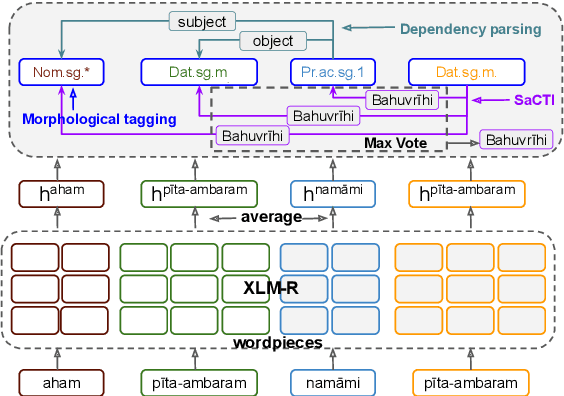
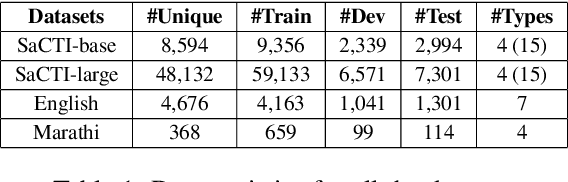
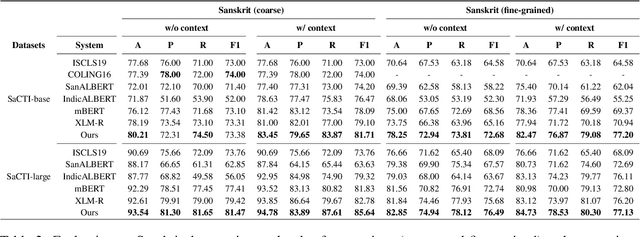
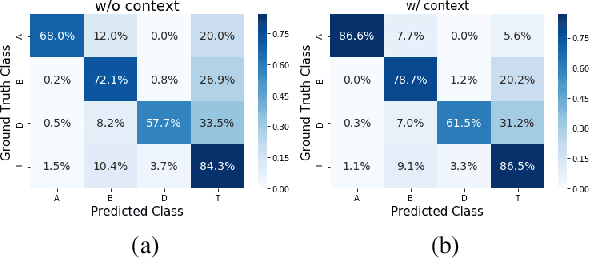
The phenomenon of compounding is ubiquitous in Sanskrit. It serves for achieving brevity in expressing thoughts, while simultaneously enriching the lexical and structural formation of the language. In this work, we focus on the Sanskrit Compound Type Identification (SaCTI) task, where we consider the problem of identifying semantic relations between the components of a compound word. Earlier approaches solely rely on the lexical information obtained from the components and ignore the most crucial contextual and syntactic information useful for SaCTI. However, the SaCTI task is challenging primarily due to the implicitly encoded context-sensitive semantic relation between the compound components. Thus, we propose a novel multi-task learning architecture which incorporates the contextual information and enriches the complementary syntactic information using morphological tagging and dependency parsing as two auxiliary tasks. Experiments on the benchmark datasets for SaCTI show 6.1 points (Accuracy) and 7.7 points (F1-score) absolute gain compared to the state-of-the-art system. Further, our multi-lingual experiments demonstrate the efficacy of the proposed architecture in English and Marathi languages.The code and datasets are publicly available at https://github.com/ashishgupta2598/SaCTI
Prabhupadavani: A Code-mixed Speech Translation Data for 25 Languages
Jan 27, 2022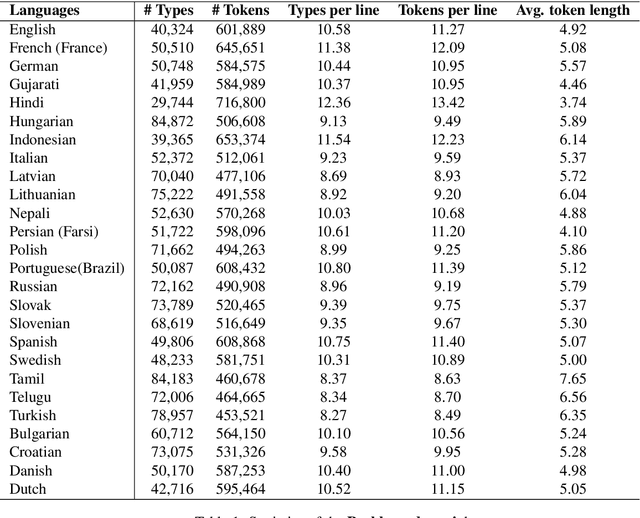
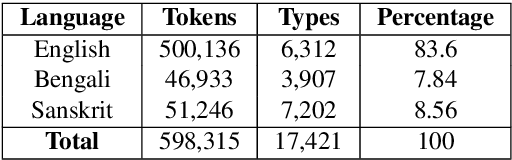


Nowadays, code-mixing has become ubiquitous in Natural Language Processing (NLP); however, no efforts have been made to address this phenomenon for Speech Translation (ST) task. This can be solely attributed to the lack of code-mixed ST task labelled data. Thus, we introduce Prabhupadavani, a multilingual code-mixed ST dataset for 25 languages, covering ten language families, containing 94 hours of speech by 130+ speakers, manually aligned with corresponding text in the target language. Prabhupadvani is the first code-mixed ST dataset available in the ST literature to the best of our knowledge. This data also can be used for a code-mixed machine translation task. All the dataset and code can be accessed at: \url{https://github.com/frozentoad9/CMST}